NVIDIA Announces CUDA 6: Unified Memory for CUDA
by Ryan Smith on November 14, 2013 9:00 AM EST
Kicking off next week will be the annual International Conference for High Performance Computing, Networking, Storage, and Analysis, better known as SC. For NVIDIA, next to their annual GPU Technology Conference, SC is their second biggest GPU compute conference, and is typically the venue for NVIDIA’s summer/fall announcements. To that end NVIDIA has a number of announcements lined up for this year, so many in fact that they’re pushing out some of them ahead of the conference just to keep them from being overwhelming. The most important of those announcements in turn will be the announcement of the next version of CUDA, CUDA 6.
Unlike some prior CUDA releases, NVIDIA isn’t touting a large number of new features for this version of CUDA. But what few elements NVIDIA is working on are going to be very significant.
The big news here – and the headlining feature for CUDA 6 – is that NVIDIA has implemented complete unified memory support within CUDA. The toolkit has possessed unified virtual addressing support since CUDA 4, allowing the disparate x86 and GPU memory pools to be addressed together in a single space. But unified virtual addressing only simplified memory management; it did not get rid of the required explicit memory copying and pinning operations necessary to bring over data to the GPU first before the GPU could work on it.

With CUDA 6 NVIDIA has finally taken the next step towards removing those memory copies entirely, by making it possible to abstract the memory management away from the programmer. This is achieved through the CUDA 6 unified memory implementation, which implements a unified memory system on top of the existing memory pool structure. With unified memory, programmers can access any resource or address within the legal address space, regardless of which pool the address actually resides in, and operate on its contents without first explicitly copying the memory over.
Now to be clear here, CUDA 6’s unified memory system doesn’t resolve the technical limitations that require memory copies – specifically, the limited bandwidth and latency of PCIe – rather it’s a change in who’s doing the memory management. Data still needs to be copied to the GPU to be operated upon, but whereas CUDA 5 required explicit memory operations (higher level toolkits built on top of CUDA withstanding) CUDA 6 offers the ability to have CUDA do it instead, freeing the programmer from the task.

The end result as such isn’t necessarily a shift in what CUDA devices can do or their performance while doing it since the memory copies didn’t go away, but rather it further simplifies CUDA programming by removing the need for programmers to do it themselves. This in turn is intended to make CUDA programming more accessible to wider audiences that may not have been interested in doing their own memory management, or even just freeing up existing CUDA developers from having to do it in the future, speeding up code development.
With that said NVIDIA isn’t talking about the performance impact at this time. Memory abstractions such as these typically have some kind of performance penalty over manual memory management – after all, who knows more about the memory needs of an application than an application itself – but of course manual memory management isn’t going anywhere, as there will still be scenarios where the higher complexity is worth the tradeoff.
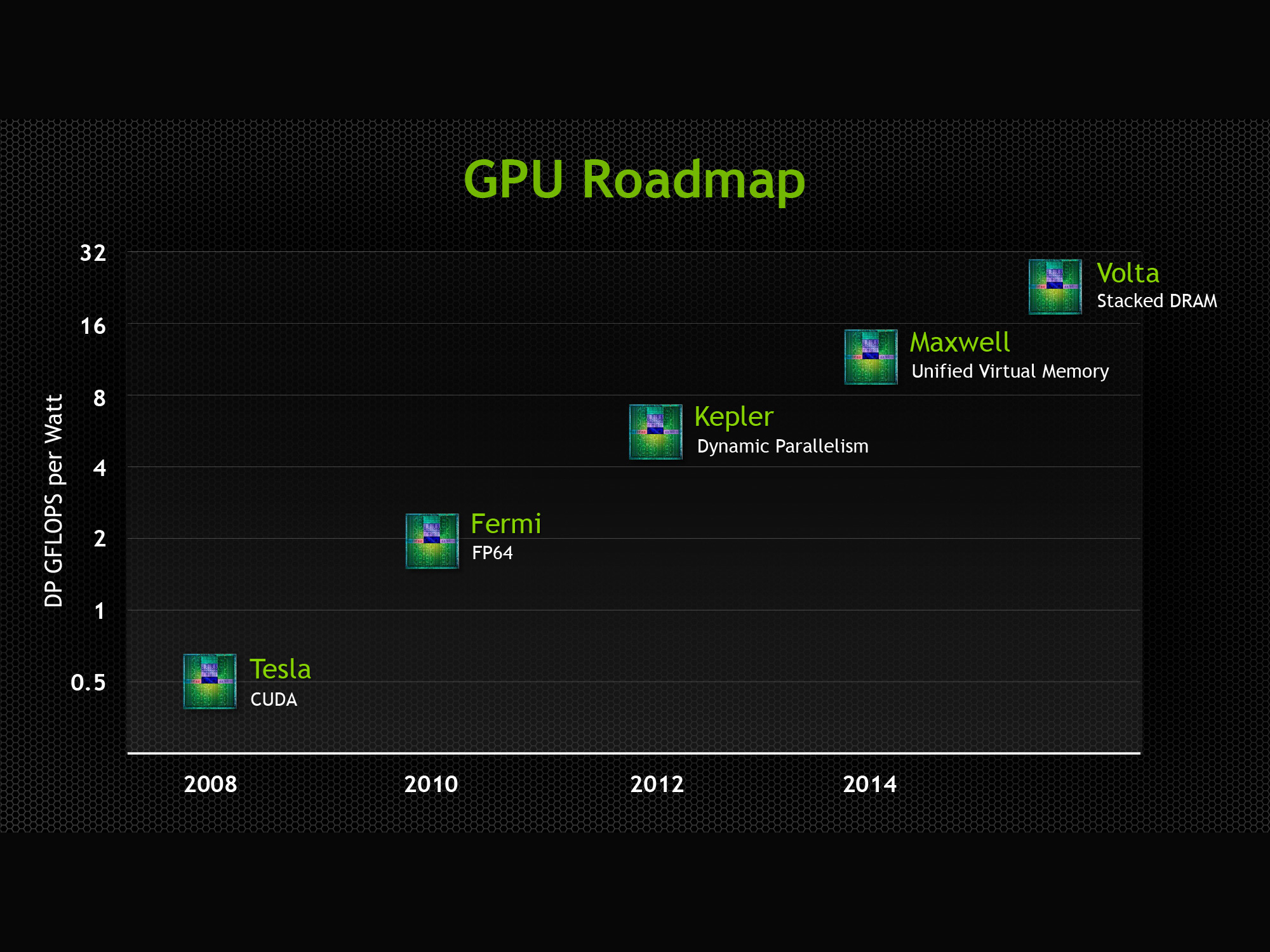
Meanwhile it’s interesting to note that this comes ahead of NVIDIA’s upcoming Maxwell GPU architecture, whose headline feature is also unified memory. From what NVIDIA is telling us they developed the means to offer a unified memory implementation today entirely in software, so they went ahead and developed that ahead of Maxwell’s release. Maxwell will have some kind of hardware functionality for implementing unified memory (and presumably better performance for it), though it’s not something NVIDIA is talking about until Maxwell is ready for its full unveiling. In the interim NVIDIA has laid the groundwork for what Maxwell will bring by getting unified memory into the toolkit before Maxwell even ships.
Moving on, there are a pair of further, smaller additions that will be coming to CUDA with CUDA 6. The first of these is that CUDA 6 will come with new BLAS and FFT libraries that are further tuned for multi-GPU scaling, with these new libraries supporting scaling of up to 8 GPUs in a node. Meanwhile NVIDIA will also be releasing drop-in compatible libraries for BLAS and FFTW, allowing applications that use those libraries to use the GPU accelerated version of their respective routines just by replacing the library.
Wrapping things up, NVIDIA will be showing off CUDA 6 and the rest of their announcement at SC13 next week. Meanwhile we’ll be back on Monday with coverage of the rest of NVIDIA’s SC13 announcements.








43 Comments
View All Comments
tipoo - Thursday, November 14, 2013 - link
So this is just for developer simplicity, it doesn't really have the benefits of true unified memory and will still need to swap over PCI-E, which I've heard can take so much time that many GPGPU operations are rendered useless as it would take less time to do traditionally. Unified memory is really the way to go in the future, if only system memory could feed beefier GPUs.tipoo - Thursday, November 14, 2013 - link
Maybe that's the point of Volta with stacked DRAM.Nenad - Friday, November 15, 2013 - link
I think Volta would only change where physically DRAM is, but Maxwell already should support single (same) DRAM for both CPU and GPU.Anyway, I see big advantage of CUDA6 in allowing you to write program today that will use advantages of unified memory tomorrow, by simply skipping behind-the-scene copy when it detect real unified memory.
For example my current CUDA apps, where I manually copy to/from GPU mem, will work sub-optimally on future Maxwell GPU with unified memory, since it will uselessly copy data from DRAM to that same DRAM. And while Nvidia can *try* to make CUDA CPU2GPU procedures 'smart' on future unified mem GPUs (to skip copy even with explicit copy command), that wont work every time, since sometimes my app rely on fact that GPU will work on its own copy while I can use original 'CPU side' data for other stuff. And its doubtful compiler can 100% detect such cases. On the other hand, with CUDA6, there is no doubt optimization can be made to skip copy on unified system.
Flunk - Thursday, November 14, 2013 - link
How would you expect the data to get from system RAM to the GPU's RAM without PCI-E? "true" unified memory requires actually unifying the memory architecture, such as is done with AMD Fusion APUs. You can't change hardware details with a software API.
andrewaggb - Thursday, November 14, 2013 - link
well it should allow for code written now to run faster if future hardware does have unified memory. The copies might not even be necessary and this can be handled behind the scenes. At least that's what I get out of it.But I agree that AMD's approach with apu's and unified memory seems like where the big gpu compute gains will come from. At least it should be usable for all the scenerios where pci overhead are significant, though faster external gpu's might still be better for some tasks.
Should be interesting.
extide - Thursday, November 14, 2013 - link
With a discrete GPU that has different physical memory than the CPU there will ALWAYS be a need to copy the memory back and forth. Whether it's done behind the scenes or not really doesnt matter in the performance sense. This is really a non-event in my book, I mean sure it's cool to have some things done automatically but the performance gains come from having physically the same memory, not the other way around.Yojimbo - Friday, November 15, 2013 - link
I suppose you do all your coding in assemblytipoo - Thursday, November 14, 2013 - link
Which was exactly my point.Kevin G - Thursday, November 14, 2013 - link
nVidia is going the other other direction: it is building an ARM CPU into their future GPU's. See Project Denver. This way they can pawn off all the necessary CPU tasks as much as possible to a localized processor and side step the latency and bandwidth issues of PCI-e and the host CPU.lours - Thursday, November 14, 2013 - link
Big marketing shot to try minimize the impact from AMD hUMA.