The Next Generation Open Compute Hardware: Tried and Tested
by Johan De Gelas & Wannes De Smet on April 28, 2015 12:00 PM EST
Four years ago we reviewed Facebook's self-designed and open source server, Freedom. Coinciding with releasing their datacenter design, they founded the Open Compute Foundation, creating a home for the design documents, licenses and bringing vendors together under one roof.
Today, the Open Compute Foundation is doing well. Many high profile companies such as Yandex, IBM and Intel are members, and in 2014 Microsoft joined the initiative as a second major open hardware partner; releasing its Open Cloud Server designs to a pool of open hardware spanning everything from servers and switches to datacenters. The international community has grown substantially, with Summits in all major continents attracting a larger crowd each time. More so, the number of companies adopting hardware from OCP and contributing back is rising as well, and with good reason: Mark Zuckerberg indicated at the 2015 Summit in San Diego that Facebook achieved a $2 billion (USD) cost reduction (!), achieved in part by using open purpose-built hardware instead of regular proprietary gear.
To Follow and Like, at Scale
When Facebook talks about the incredible amounts of money it has saved by using Open Compute, keep in mind that even though the vanity-free hardware is designed to be cost-effective, it's the actual software that enables hardware efficiency. The company has always sought to use commonly available software components to build its services, and when it picked one, plenty of time and money are spent on performance engineering to optimize the software. Performance engineering that enables Facebook to handle 6 billion likes, 930 million photos and 12 billion messages every day, and those numbers only represent activity its social network product generates; Instagram and WhatsApp are not exactly toy workloads either.
Facebook has carried out plenty of improvements in open-source projects, or started new implementations, most of them contributed back to the community, good karma indeed. Notable performance-related projects are HHVM -- short for HipHop VM, a JIT'ing PHP virtual machine with its own PHP language dialect called Hack, adding static typing in the mix. HHVM is advertised as 'a more predictable PHP', and if Wikipedia's migration serves as any indication it makes existing PHP powered sites quite a bit faster as well. Another initiative called rocksdb, implements a properly scaleable, persistent key-value store for fast storage written in C++ and presto, a distributed SQL engine for Big Data stored in common storage systems like Cassandra, JDBC DBs and HDFS. Presto provides functionality similar to Hive, and is currently in use at Dropbox and Airbnb.
Scale Your Devops
A (dev)ops engineer at Facebook can request any kind of hardware configuration he likes, as long it is one of the following five:
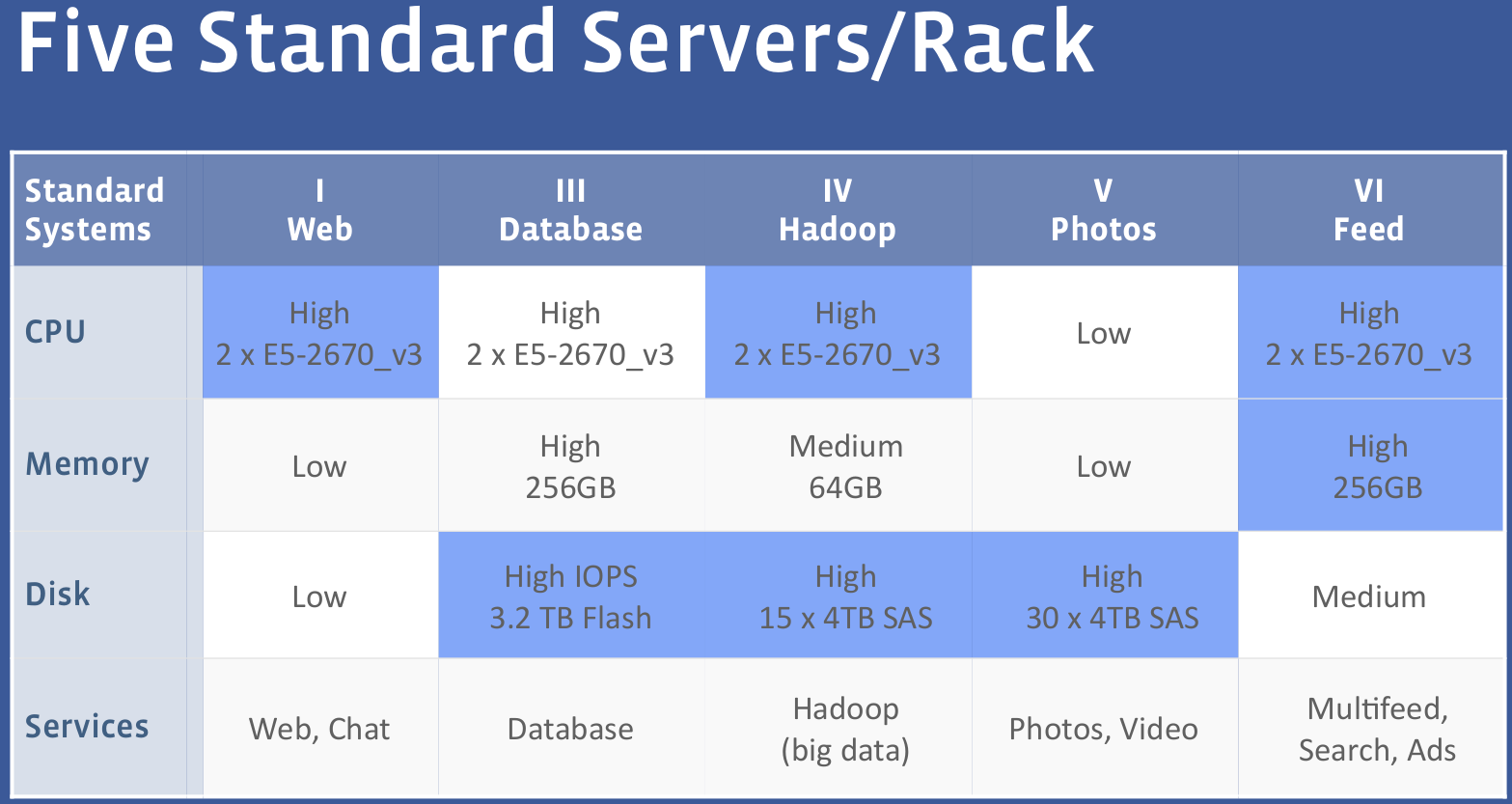
Increasing the number of parts used in your systems exponentially increases the amount of money and time that will be spent in procuring, validation and maintenance. And keep in mind that in order to avoid vendor lock-in, each configuration must be available from at least two suppliers, so it's easy to imagine why FB prefers to keep it simple when it comes to servers: 5 SKUs using the same base platform, each targeted at a certain kind of application.
The SKUs mentioned are variations on Facebook's latest Xeon E5 server platform, Leopard, reviewed in detail in this article. The web tier is concerned with gathering every piece of information from the entire stack and rendering it to HTML/JSON, for which it needs a decent CPU, but not much else. Object storage, like photos is quite the opposite, and requires just a simple CPU (Atom C2000) to serve object from a large storage backend. At the other end of the spectrum, you have the data crunching units that require a decent chunk of processing power, memory capacity and I/O.








26 Comments
View All Comments
Black Obsidian - Tuesday, April 28, 2015 - link
I've always hoped for more in-depth coverage of the OpenCompute initiative, and this article is absolutely fantastic. It's great to see a company like Facebook innovating and contributing to the standard just as much as (if not more than) the traditional hardware OEMs.ats - Tuesday, April 28, 2015 - link
You missed the best part of the MS OCS v2 in your description: support for up to 8 M.2 x4 PCIe 3.0 drives!nmm - Tuesday, April 28, 2015 - link
I have always wondered why they bother with a bunch of little PSU's within each system or rack to convert AC power to DC. Wouldn't it make more sense to just provide DC power to the entire room/facility, then use less expensive hardware with no inverter to convert it to the needed voltages near each device? This type of configuration would get along better with battery backups as well, allowing systems to run much longer on battery by avoiding the double conversion between the battery and server.extide - Tuesday, April 28, 2015 - link
The problem with doing a datacenter wide power distribution is that at only 12v, to power hundreds of servers you would need to provide thousands of amps, and it is essentially impossible to do that efficiently. Basicaly the way FB is doing it, is the way to go -- you keep the 12v current to reasonable levels and only have to pass that high current a reasonable distance. Remember 6KW at 12v is already 500A !! And thats just for HALF of a rack.tspacie - Tuesday, April 28, 2015 - link
Telcos have done this at -48VDC for a while. I wonder did data center power consumption get too high to support this, or maybe just the big data centers don't have the same continuous up time requirements ?Anyway, love the article.
Notmyusualid - Wednesday, April 29, 2015 - link
Indeed.In the submarine cable industry (your internet backbone), ALL our equipment is -48v DC. Even down to routers / switches (which are fitted with DC power modules, rather than your normal 100 - 250v AC units one expects to see).
Only the management servers run from AC power (not my decision), and the converters that charge the DC plant.
But 'extide' has a valid point - the lower voltage and higher currents require huge cabling. Once a electrical contractor dropped a piece of metal conduit from high over the copper 'bus bars' in the DC plant. Need I describe the fireworks that resulted?
toyotabedzrock - Wednesday, April 29, 2015 - link
48 v allows 4 times the power at a given amperage.12vdc doesn't like to travel far and at the needed amperage would require too much expensive copper.
I think a pair of square wave pulsed DC at higher voltage could allow them to just use a transformer and some capacitors for the power supply shelf. The pulses would have to be directly opposing each other.
Jaybus - Tuesday, April 28, 2015 - link
That depends. The low voltage DC requires a high current, and so correspondingly high line loss. Line loss is proportional to the square of the current, so the 5V "rail" will have more than 4x the line loss of the 12V "rail", and the 3.3V rail will be high current and so high line loss. It is probably NOT more efficient than a modern PS. But what it does do is move the heat generating conversion process outside of the chassis, and more importantly, frees up considerable space inside the chassis.Menno vl - Wednesday, April 29, 2015 - link
There is already a lot of things going on in this direction. See http://www.emergealliance.org/and especially their 380V DC white paper.
Going DC all the way, but at a higher voltage to keep the demand for cables reasonable. Switching 48VDC to 12VDC or whatever you need requires very similar technology as switching 380VDC to 12VDC. Of-course the safety hazards are different and it is similar when compared to mixing AC and DC which is a LOT of trouble.
Casper42 - Monday, May 4, 2015 - link
Indeed, HP already makes 277VAC and 380VDC Power Supplies for both the Blades and Rackmounts.277VAC is apparently what you get when you split 480vAC 3phase into individual phases..